
SSE2, short for Streaming SIMD Extensions 2, was one of the most important instruction-set extensions in the history of x86 processors.
It was introduced by Intel with the Pentium 4 processor, code-named Willamette, as the successor to the original SSE instruction set. At the time, SSE2 was presented as an extension of both MMX and SSE. In practice, it became much more than that.
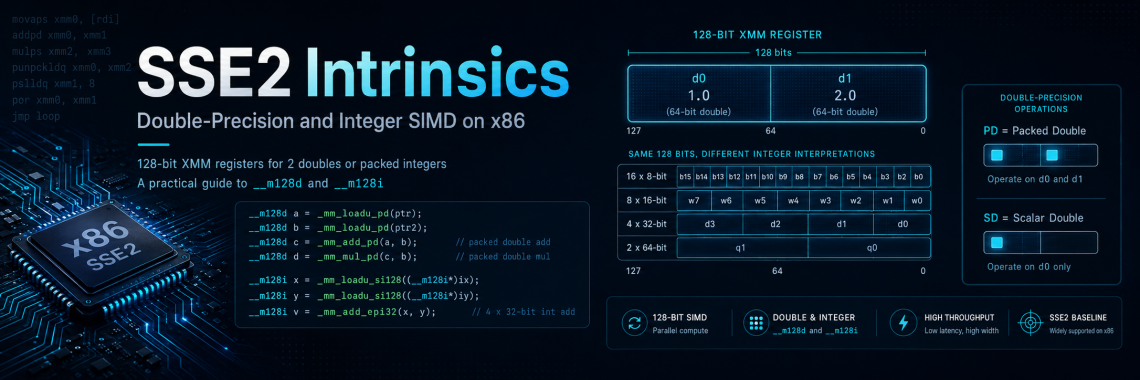
SSE2 completed the transition from the old 64-bit MMX programming model to the cleaner and more powerful 128-bit XMM register model.
The original SSE instruction set had already introduced XMM registers and 128-bit packed single-precision floating-point operations. SSE2 expanded that model in two major directions:
- it added double-precision floating-point SIMD;
- it added 128-bit packed integer SIMD, making XMM registers a practical replacement for MMX.
That is why SSE2 is still important today. It is not just an old Pentium 4 feature. It is part of the baseline for x86-64 software and remains the minimum SIMD foundation for most modern 64-bit x86 code.
The Short Version
SSE2 added three essential capabilities to x86 SIMD programming:
- Packed double-precision floating-point operations
- Scalar double-precision floating-point operations
- 128-bit integer SIMD operations using XMM registers
Before SSE2, integer SIMD code mostly used MMX registers. MMX registers were only 64 bits wide and shared state with the old x87 floating-point unit.
With SSE2, integer SIMD could move to 128-bit XMM registers.
That meant more data per instruction, cleaner state management, and a better programming model for future SIMD extensions.
SSE2 in the Evolution of x86 SIMD
To understand SSE2, it helps to place it in the SIMD timeline.
| Instruction set | Main register type | Register width | Main contribution |
|---|---|---|---|
| MMX | MMX registers | 64-bit | Packed integer SIMD |
| SSE | XMM registers | 128-bit | Packed single-precision floating-point SIMD |
| SSE2 | XMM registers | 128-bit | Double-precision floating point and 128-bit integer SIMD |
| SSE3 / SSSE3 / SSE4 | XMM registers | 128-bit | More arithmetic, shuffle, text, and media instructions |
| AVX | YMM registers | 256-bit | Wider floating-point SIMD and better instruction encoding |
| AVX2 | YMM registers | 256-bit | Wider integer SIMD |
| AVX-512 | ZMM registers | 512-bit | Wider vectors, masks, and many specialized extensions |
MMX introduced SIMD to mainstream x86 programming.
SSE introduced XMM registers and 128-bit floating-point vectors.
SSE2 made XMM registers the central SIMD register file for both floating-point and integer work.
What SSE2 Added Over SSE
The original SSE instruction set focused mostly on single-precision floating-point values.
One XMM register could hold four 32-bit floats:
float0 float1 float2 float3
SSE2 added support for double-precision floating-point values.
One XMM register can hold two 64-bit doubles:
double0 double1
SSE2 also added 128-bit packed integer operations.
One XMM register can hold:
| Data type | Elements per XMM register |
|---|---|
| 8-bit integers | 16 |
| 16-bit integers | 8 |
| 32-bit integers | 4 |
| 64-bit integers | 2 |
| 32-bit floats | 4 |
| 64-bit doubles | 2 |
This made SSE2 useful for a much wider set of algorithms than the original SSE.
The Four Main Groups of SSE2 Instructions
SSE2 instructions can be grouped into four broad categories:
- packed and scalar double-precision floating-point instructions;
- floating-point and integer conversion instructions;
- 128-bit SIMD integer instructions;
- cache-control and memory-ordering instructions.
Each category solved a different problem.
1. Double-Precision Floating-Point Instructions
The original SSE instruction set worked with 32-bit single-precision floating-point values.
SSE2 added 64-bit double-precision floating-point support.
This was extremely important because many scientific, engineering, financial, and general-purpose numerical applications require double precision.
SSE2 supports both packed and scalar double-precision operations.
Packed Double-Precision Operations
Packed operations process two double-precision values at once.
Example:
#include <emmintrin.h>
void add_two_doubles(double* dst, const double* a, const double* b)
{
__m128d va = _mm_loadu_pd(a);
__m128d vb = _mm_loadu_pd(b);
__m128d vr = _mm_add_pd(va, vb);
_mm_storeu_pd(dst, vr);
}
This computes:
dst[0] = a[0] + b[0]
dst[1] = a[1] + b[1]
with one packed SSE2 addition instruction.
Common packed double-precision intrinsics include:
| Intrinsic | Operation |
|---|---|
_mm_add_pd | add two packed doubles |
_mm_sub_pd | subtract two packed doubles |
_mm_mul_pd | multiply two packed doubles |
_mm_div_pd | divide two packed doubles |
_mm_sqrt_pd | square root of two packed doubles |
_mm_min_pd | minimum of two packed doubles |
_mm_max_pd | maximum of two packed doubles |
Scalar Double-Precision Operations
SSE2 also supports scalar double-precision operations. These operate only on the lowest double-precision element of an XMM register.
Example:
#include <emmintrin.h>
double add_one_double(double a, double b)
{
__m128d va = _mm_set_sd(a);
__m128d vb = _mm_set_sd(b);
__m128d vr = _mm_add_sd(va, vb);
return _mm_cvtsd_f64(vr);
}
Common scalar double-precision intrinsics include:
| Intrinsic | Operation |
|---|---|
_mm_add_sd | add scalar double |
_mm_sub_sd | subtract scalar double |
_mm_mul_sd | multiply scalar double |
_mm_div_sd | divide scalar double |
_mm_sqrt_sd | square root of scalar double |
_mm_min_sd | minimum of scalar double |
_mm_max_sd | maximum of scalar double |
Scalar SSE2 double instructions helped compilers move ordinary double-precision arithmetic away from the old x87 floating-point stack and into XMM registers.
That was a major architectural improvement.
2. Integer SIMD in XMM Registers
The most important long-term contribution of SSE2 was not just double-precision arithmetic.
It was the move of packed integer SIMD from MMX registers to XMM registers.
MMX code used 64-bit MMX registers:
mm0 mm1 mm2 mm3 mm4 mm5 mm6 mm7
SSE2 integer code uses 128-bit XMM registers:
xmm0 xmm1 xmm2 xmm3 ...
In C/C++ intrinsics, this means moving from:
__m64
to:
__m128i
This doubled the SIMD width for packed integer operations.
MMX vs SSE2 Integer SIMD
| Feature | MMX | SSE2 |
|---|---|---|
| Register type | MMX | XMM |
| Register width | 64-bit | 128-bit |
| Intrinsic type | __m64 | __m128i |
| Packed bytes | 8 | 16 |
| Packed 16-bit words | 4 | 8 |
| Packed 32-bit integers | 2 | 4 |
| Packed 64-bit integers | 1 | 2 |
| Shares state with x87 | Yes | No |
Requires _mm_empty() | Yes | No |
This is why SSE2 largely replaced MMX for new integer SIMD code.
Example: Adding Packed Bytes
Here is a simple SSE2 function that adds unsigned bytes with wraparound arithmetic:
#include <stdint.h>
#include <stddef.h>
#include <emmintrin.h>
void add_bytes_sse2(
uint8_t* dst,
const uint8_t* a,
const uint8_t* b,
size_t count)
{
size_t i = 0;
for (; i + 16 <= count; i += 16)
{
__m128i va = _mm_loadu_si128((const __m128i*)(a + i));
__m128i vb = _mm_loadu_si128((const __m128i*)(b + i));
__m128i vr = _mm_add_epi8(va, vb);
_mm_storeu_si128((__m128i*)(dst + i), vr);
}
for (; i < count; ++i)
{
dst[i] = (uint8_t)(a[i] + b[i]);
}
}
This processes sixteen bytes per loop iteration.
The equivalent MMX version would process only eight bytes per iteration and would require _mm_empty() before returning to code that might use x87 floating-point operations.
Saturating Integer Arithmetic
One of the reasons MMX was popular for multimedia programming was its support for saturating arithmetic.
SSE2 keeps that style of operation, but extends it to 128-bit XMM registers.
Saturating arithmetic clamps results instead of wrapping around.
For unsigned 8-bit values:
250 + 20 = 14 // normal wraparound arithmetic
250 + 20 = 255 // saturating arithmetic
SSE2 example:
#include <stdint.h>
#include <stddef.h>
#include <emmintrin.h>
void brighten_image_sse2(uint8_t* pixels, uint8_t amount, size_t count)
{
size_t i = 0;
__m128i increment = _mm_set1_epi8((char)amount);
for (; i + 16 <= count; i += 16)
{
__m128i p = _mm_loadu_si128((const __m128i*)(pixels + i));
__m128i r = _mm_adds_epu8(p, increment);
_mm_storeu_si128((__m128i*)(pixels + i), r);
}
for (; i < count; ++i)
{
unsigned int value = pixels[i] + amount;
pixels[i] = (value > 255) ? 255 : (uint8_t)value;
}
}
This kind of operation is useful for:
- image brightness adjustment;
- alpha blending;
- audio sample processing;
- pixel format conversion;
- video filters.
Common SSE2 Integer Instructions
SSE2 includes many packed integer operations that mirror or extend MMX functionality.
| Operation type | Example intrinsics |
|---|---|
| Add | _mm_add_epi8, _mm_add_epi16, _mm_add_epi32, _mm_add_epi64 |
| Subtract | _mm_sub_epi8, _mm_sub_epi16, _mm_sub_epi32, _mm_sub_epi64 |
| Saturating add | _mm_adds_epi8, _mm_adds_epu8, _mm_adds_epi16, _mm_adds_epu16 |
| Saturating subtract | _mm_subs_epi8, _mm_subs_epu8, _mm_subs_epi16, _mm_subs_epu16 |
| Compare | _mm_cmpeq_epi8, _mm_cmpeq_epi16, _mm_cmpeq_epi32 |
| Compare greater-than | _mm_cmpgt_epi8, _mm_cmpgt_epi16, _mm_cmpgt_epi32 |
| Multiply | _mm_mullo_epi16, _mm_mulhi_epi16, _mm_mulhi_epu16, _mm_mul_epu32 |
| Unpack | _mm_unpacklo_epi8, _mm_unpackhi_epi8, _mm_unpacklo_epi16, _mm_unpackhi_epi16 |
| Shift | _mm_slli_epi16, _mm_srli_epi16, _mm_srai_epi16, _mm_slli_epi32, _mm_srli_epi32 |
| Logical | _mm_and_si128, _mm_or_si128, _mm_xor_si128, _mm_andnot_si128 |
This made SSE2 a practical target for many integer-heavy algorithms that previously used MMX.
3. Conversion Instructions
SSE2 also added conversion instructions between integers, single-precision floats, and double-precision floats.
These are important because real programs often need to move between representations.
For example:
- image pixels may start as integers and be processed as floats;
- audio samples may be converted to floating point for filtering;
- floating-point results may need to be converted back to integers;
- single-precision data may need to be converted to double precision for accuracy;
- double-precision results may need to be converted back to single precision for storage.
Examples of SSE2 conversion intrinsics include:
| Intrinsic | Meaning |
|---|---|
_mm_cvtepi32_ps | convert four 32-bit integers to four floats |
_mm_cvtps_epi32 | convert four floats to four 32-bit integers using rounding |
_mm_cvttps_epi32 | convert four floats to four 32-bit integers using truncation |
_mm_cvtepi32_pd | convert two 32-bit integers to two doubles |
_mm_cvtpd_epi32 | convert two doubles to 32-bit integers |
_mm_cvtps_pd | convert two floats to two doubles |
_mm_cvtpd_ps | convert two doubles to two floats |
_mm_cvtsi32_sd | convert one 32-bit integer to scalar double |
_mm_cvtsd_si32 | convert scalar double to 32-bit integer |
_mm_cvttsd_si32 | convert scalar double to 32-bit integer using truncation |
Example: Integer to Float Conversion
#include <emmintrin.h>
void convert_ints_to_floats(float* dst, const int* src)
{
__m128i integers = _mm_loadu_si128((const __m128i*)src);
__m128 floats = _mm_cvtepi32_ps(integers);
_mm_storeu_ps(dst, floats);
}
This converts four signed 32-bit integers into four single-precision floating-point values.
Example: Float to Integer Conversion
#include <emmintrin.h>
void convert_floats_to_ints(int* dst, const float* src)
{
__m128 floats = _mm_loadu_ps(src);
__m128i integers = _mm_cvttps_epi32(floats);
_mm_storeu_si128((__m128i*)dst, integers);
}
The intrinsic _mm_cvttps_epi32 truncates toward zero.
This is usually the behavior expected from a C-style cast from float to int.
The non-truncating version, _mm_cvtps_epi32, uses the current SSE rounding mode.
Rounding vs Truncation
SSE2 provides both rounded and truncating conversions.
The distinction matters.
| Intrinsic | Behavior |
|---|---|
_mm_cvtps_epi32 | converts floats to integers using the current rounding mode |
_mm_cvttps_epi32 | converts floats to integers by truncating toward zero |
_mm_cvtpd_epi32 | converts doubles to integers using the current rounding mode |
_mm_cvttpd_epi32 | converts doubles to integers by truncating toward zero |
_mm_cvtsd_si32 | converts scalar double to integer using the current rounding mode |
_mm_cvttsd_si32 | converts scalar double to integer by truncating toward zero |
If you want C-style truncation, use the cvtt version.
4. Cache Control and Memory Ordering
SSE2 also added instructions related to cache control and memory ordering.
These are not arithmetic instructions, but they matter in high-performance systems programming.
Important examples include:
| Instruction | Purpose |
|---|---|
CLFLUSH | flush a cache line |
LFENCE | serialize load operations |
MFENCE | serialize load and store operations |
MOVNTDQ | non-temporal store from XMM register |
MOVNTPD | non-temporal store of packed doubles |
MOVNTI | non-temporal integer store |
MASKMOVDQU | masked non-temporal byte store |
PAUSE | improve spin-wait loop behavior |
Non-temporal stores are useful when writing large amounts of data that will not be reused soon.
For example, a video processing routine might write a large output frame. If the output frame is not read again immediately, non-temporal stores may reduce cache pollution.
However, these instructions should be used carefully. Modern CPUs already have sophisticated caches and prefetchers. Manual cache-control instructions can improve performance in some streaming workloads, but they can also make code slower if used incorrectly.
Always measure.
SSE2 Load and Store Instructions
SSE2 code often begins and ends with loads and stores.
For integer data, the most common intrinsics are:
_mm_loadu_si128
_mm_storeu_si128
These perform unaligned 128-bit loads and stores.
Example:
__m128i v = _mm_loadu_si128((const __m128i*)ptr);
_mm_storeu_si128((__m128i*)dst, v);
For aligned data, SSE2 provides:
_mm_load_si128
_mm_store_si128
These require 16-byte alignment.
Example:
__m128i v = _mm_load_si128((const __m128i*)ptr);
_mm_store_si128((__m128i*)dst, v);
Use aligned loads and stores only when the pointer is guaranteed to be aligned to a 16-byte boundary.
If alignment is unknown, use the unaligned versions.
16-Byte Alignment
A 128-bit XMM register is 16 bytes wide.
Some SSE2 memory operations require 16-byte aligned addresses.
An address is 16-byte aligned when:
address % 16 == 0
Examples:
0x1000 aligned
0x1010 aligned
0x1020 aligned
Examples of unaligned addresses:
0x1001 unaligned
0x1008 unaligned
0x100C unaligned
Early SSE and SSE2 code often spent a lot of effort on alignment because aligned loads and stores could be significantly faster, and some aligned instructions would fault on unaligned addresses.
Modern CPUs handle unaligned accesses much better, but alignment still matters for peak performance in some loops.
The safe default is:
_mm_loadu_si128
_mm_storeu_si128
Then optimize alignment only when profiling shows a reason.
SSE2 and MMX
SSE2 is often described as extending MMX instructions to 128 bits.
That is a useful simplification, but the details matter.
MMX uses __m64 and 64-bit MMX registers.
SSE2 uses __m128i and 128-bit XMM registers.
Example MMX-style operation:
#include <mmintrin.h>
void mmx_example(void)
{
__m64 a = _mm_set_pi16(4, 3, 2, 1);
__m64 b = _mm_set_pi16(8, 7, 6, 5);
__m64 c = _mm_add_pi16(a, b);
_mm_empty();
}
Equivalent SSE2-style operation:
#include <emmintrin.h>
void sse2_example(void)
{
__m128i a = _mm_set_epi16(8, 7, 6, 5, 4, 3, 2, 1);
__m128i b = _mm_set_epi16(16, 15, 14, 13, 12, 11, 10, 9);
__m128i c = _mm_add_epi16(a, b);
// No _mm_empty() required.
}
The lack of _mm_empty() is important.
MMX shares state with the x87 floating-point unit. SSE2 XMM registers do not.
This makes SSE2 cleaner and safer to mix with ordinary floating-point code.
SSE2 and x87 Floating Point
Before SSE and SSE2, x86 floating-point arithmetic mostly used the x87 FPU stack.
The x87 FPU model is powerful but awkward:
- it uses a stack-like register model;
- it has historical extended-precision behavior;
- it is less convenient for modern compiler register allocation;
- it does not map naturally to SIMD vectors.
SSE2 made it practical for compilers to generate scalar double-precision arithmetic using XMM registers instead of x87.
For example, a scalar double addition can be implemented with ADDSD instead of x87 stack instructions.
This was one reason SSE2 became central to modern x86 code generation.
SSE2 and x86-64
SSE2 is part of the baseline feature set for x86-64.
That means a normal 64-bit x86 program can generally assume SSE2 support.
This is one of the main reasons SSE2 remains important today. Even though newer instruction sets such as AVX2 and AVX-512 are much wider, SSE2 is still the minimum SIMD level available on essentially all x86-64 systems.
For portable 64-bit x86 code, SSE2 is the safe baseline.
A typical runtime dispatch hierarchy might look like this:
scalar fallback
SSE2
SSSE3
SSE4.1
AVX2
AVX-512
SSE2 is the first optimized SIMD step above scalar code.
SSE2 vs SSE
The difference between SSE and SSE2 can be summarized like this:
| Feature | SSE | SSE2 |
|---|---|---|
| 128-bit XMM registers | Yes | Yes |
| Packed single-precision floats | Yes | Yes |
| Scalar single-precision floats | Yes | Yes |
| Packed double-precision floats | No | Yes |
| Scalar double-precision floats | No | Yes |
| 128-bit integer SIMD | No | Yes |
| Integer SIMD replacement for MMX | Partial | Yes |
| x86-64 baseline | No | Yes |
SSE introduced the XMM register model.
SSE2 made that model complete enough to become the foundation of modern x86 SIMD programming.
SSE2 vs AVX and AVX2
SSE2 uses 128-bit XMM registers.
AVX extended the model to 256-bit YMM registers for floating-point operations.
AVX2 extended 256-bit SIMD to integer operations.
| Instruction set | Register width | Integer SIMD | Floating-point SIMD |
|---|---|---|---|
| SSE2 | 128-bit | Yes | Single and double |
| AVX | 256-bit | Limited | Single and double |
| AVX2 | 256-bit | Yes | Single and double |
| AVX-512 | 512-bit | Yes | Single and double, plus masks and many extensions |
For new high-performance code, AVX2 or AVX-512 may be better targets when available.
But SSE2 remains the compatibility foundation.
When SSE2 Is Still the Right Target
SSE2 is still useful when:
- writing portable x86-64 code;
- maintaining compatibility with old machines;
- replacing MMX routines;
- writing fallback paths for AVX2 or AVX-512 code;
- building libraries that need broad CPU coverage;
- writing educational SIMD examples.
SSE2 is no longer the fastest SIMD target, but it is one of the most widely available.
When to Use Newer SIMD Instead
Use newer instruction sets when your target hardware supports them and performance matters.
Consider:
- SSSE3 for byte shuffle operations such as
PSHUFB; - SSE4.1 for blends, dot products, and better integer operations;
- AVX2 for 256-bit integer SIMD;
- FMA for fused multiply-add floating-point code;
- AVX-512 for wide vectors, masks, and server/HPC/AI workloads.
A good modern library may contain several implementations and choose the best one at runtime.
A Practical SSE2 Example: Converting RGBA Alpha
Suppose we have an array of alpha values and want to clamp them upward so that every alpha byte is at least 32.
SSE2 does not have an unsigned byte max instruction. That came with SSE4.1 for XMM registers. But SSE2 can still implement many useful operations with comparisons, masks, and saturated arithmetic.
For simpler cases, saturating add and subtract are direct.
Here is a function that increases alpha values with saturation:
#include <stdint.h>
#include <stddef.h>
#include <emmintrin.h>
void increase_alpha_sse2(uint8_t* alpha, uint8_t amount, size_t count)
{
size_t i = 0;
__m128i inc = _mm_set1_epi8((char)amount);
for (; i + 16 <= count; i += 16)
{
__m128i a = _mm_loadu_si128((const __m128i*)(alpha + i));
__m128i r = _mm_adds_epu8(a, inc);
_mm_storeu_si128((__m128i*)(alpha + i), r);
}
for (; i < count; ++i)
{
unsigned int value = alpha[i] + amount;
alpha[i] = (value > 255) ? 255 : (uint8_t)value;
}
}
This is exactly the kind of packed byte operation where SSE2 is a natural replacement for old MMX code.
Common Mistakes
Mistake 1: Thinking SSE2 Is Only About Double-Precision Floating Point
SSE2 did add double-precision floating-point SIMD, but it also added 128-bit integer SIMD.
For many programmers, the integer side of SSE2 was just as important as the floating-point side.
Mistake 2: Treating SSE2 as MMX With Bigger Registers
SSE2 integer instructions are similar to MMX instructions, but the programming model is different.
You must update:
- register types;
- load/store instructions;
- loop increments;
- alignment assumptions;
- tail handling;
- shuffle logic;
- shift logic.
Do not simply rename MMX registers to XMM registers.
Mistake 3: Using Aligned Loads on Unaligned Data
This is unsafe unless ptr is guaranteed to be 16-byte aligned:
__m128i v = _mm_load_si128((const __m128i*)ptr);
Use this when alignment is unknown:
__m128i v = _mm_loadu_si128((const __m128i*)ptr);
Mistake 4: Keeping _mm_empty() in Pure SSE2 Code
Pure SSE2 code does not need _mm_empty().
If the function only uses XMM registers, _mm_empty() is unnecessary.
Only MMX code using __m64 or mm0–mm7 requires MMX cleanup.
Mistake 5: Assuming SSE2 Is Always Faster
SSE2 gives you wider registers than MMX and better compiler support than old x87/MMX code, but performance still depends on the workload.
Memory bandwidth, cache behavior, alignment, instruction throughput, and data layout all matter.
Always benchmark the real code on the target CPU.
Best Practices
For new SSE2 code:
- use
<emmintrin.h>; - use
__m128ifor integer vectors; - use
__m128dfor double-precision floating-point vectors; - use
_mm_loadu_si128and_mm_storeu_si128unless alignment is guaranteed; - process data in 16-byte blocks for integer byte operations;
- handle the tail with scalar code;
- avoid MMX unless maintaining old code;
- benchmark before adding more complicated alignment or prefetch logic.
For old MMX code:
- consider rewriting it using SSE2;
- replace
__m64with__m128i; - process twice as many elements per iteration;
- remove
_mm_empty()only after all MMX usage is gone; - verify every shuffle, shift, and memory access.
Summary
SSE2 was a major turning point in x86 SIMD programming.
It extended the XMM register model introduced by SSE and made it useful for both double-precision floating-point and packed integer operations.
Its most important contributions were:
- packed double-precision floating-point SIMD;
- scalar double-precision floating-point operations in XMM registers;
- 128-bit integer SIMD;
- a practical replacement path for MMX;
- conversion instructions between integers, floats, and doubles;
- cache-control and memory-ordering instructions;
- a SIMD baseline that became part of x86-64.
Today, SSE2 is no longer the newest or widest SIMD instruction set. AVX2 and AVX-512 offer much more performance potential on modern hardware.
But SSE2 remains essential because it is the portable baseline for 64-bit x86 SIMD.
If MMX introduced SIMD to x86, and SSE introduced XMM registers, then SSE2 made XMM registers the foundation of modern x86 numerical and integer SIMD programming.
References
- Intel Intrinsics Guide
- Intel 64 and IA-32 Architectures Software Developer’s Manual
- Oracle x86 Assembly Language Reference: SSE2 Instructions
- Oracle x86 Assembly Language Reference: SSE2 128-bit SIMD Integer Instructions
- Microsoft x86 Intrinsics List
- openSUSE: x86-64 Microarchitecture Levels
- Agner Fog Optimization Manuals


