
In the AltaPixShare software app, when the user drags a group of images to the target location, the following code iterates over the list of images, and for each image creates the destination file: {CODE brush: delphi; ruler: true;}for i := 0 to Pred(ActiveImages.Count) do begin try CurrentImage := TProcessedImage(ActiveImages[i]);…
-
-

-
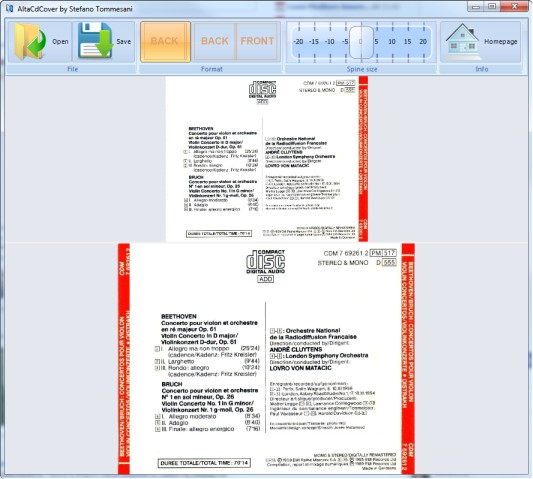
Quickly convert a digipak CD cover into a traditional jewel-box CD back cover! Just drop the CD cover to convert into the source area, AltaCdCover will automatically recognize if it contains both front and back sides or only the back side, drop the front side if found, and reconstruct the…
-

You’re having a chat on Skype with a friend of yours, talking about your last holiday, and then you want to send him some pictures. Your new 16 megapixel camera takes amazing pictures, so you drop them in the chat window, and… it takes forever to send them! In fact,…
-

The AltaLux image enhancement filter is now available in the popular XnView image viewer! Now you can enjoy AltaLux technology inside an advanced image viewer and editor, so trying how AltaLux can effectively enhance your photos is just a click away while you keep using your favourite image viewer.
-

AltaSonita is an image denoising application built to run on nVidia video boards using CUDA technology. Three different denoising algorithms, and five intensity levels let you remove most of noise from photos without blurring small details and edges. AltaSonita is provided as free software, and you can download it from…
-
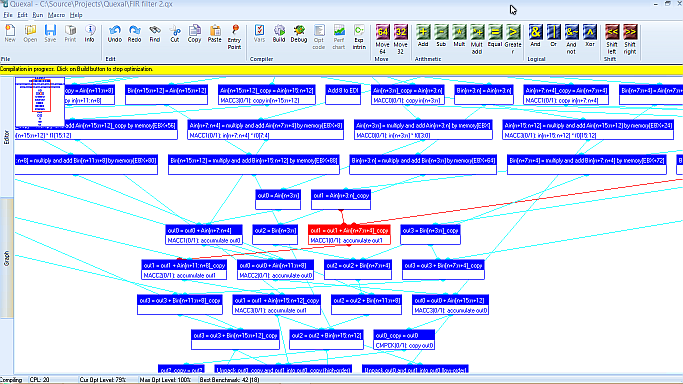
Back in 2000, Quexal changed the way programmers had to deal with MMX programming. A friendly user interface simplified building parallel versions of algorithms, an optimizing compiler made sure that the resulting code would run fast, and a visual debugger helped pinpoint programming errors. Even if the focus of the…
-

The Contact form in Joomla! uses the mail server settings to send the contact request email to the site administrator. However, when using SMTP servers (I’ve tried both Yahoo! and GMail SMTP servers), it does not work, as the email address of the sender is not recognized by the SMTP…
-
AltaLux is an image processing technology that can significantly enhance the quality of images and videos with poor lighting conditions. AltaLux/Demo is a Windows sample application that lets you enhance the quality of JPEG images for free (download it! from the download area). For even better usability, I strongly recommend…
-
A new article about using Intel TBB is here. It contains examples using C++ lambdas and joining multi-threaded loops with SIMD code In this article we will transform a plain C loop into a multi-threaded version using Intel Thread Building Blocks library (TBB). Here is the loop to transform: {CODE…