
SSE2 extends the original SSE instruction set with support for double-precision floating-point arithmetic and a wider set of integer SIMD operations.
The original SSE instructions operate mainly on four 32-bit single-precision floating-point values stored in a 128-bit XMM register. SSE2 adds the ability to operate on two 64-bit double-precision floating-point values in the same kind of register. It also adds integer SIMD operations using XMM registers, replacing many older MMX-based techniques with a cleaner 128-bit model.
This article introduces the most important SSE2 data types, naming conventions, arithmetic intrinsics, integer operations, memory operations, conversions, and common pitfalls.
What SSE2 adds over SSE
SSE introduced packed single-precision arithmetic. A 128-bit XMM register can contain four 32-bit floats:
[ f0 | f1 | f2 | f3 ]
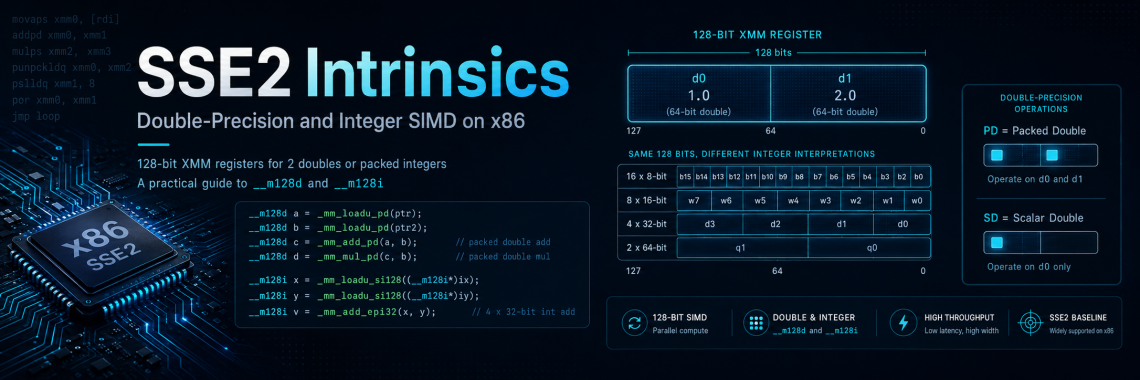
SSE2 adds packed double-precision arithmetic. The same 128-bit register can contain two 64-bit doubles:
[ d0 | d1 ]
SSE2 also adds integer SIMD support using the __m128i type. A 128-bit integer vector can be interpreted in several ways:
16 x 8-bit integers
8 x 16-bit integers
4 x 32-bit integers
2 x 64-bit integers
The instruction or intrinsic determines how the bits are interpreted.
Header file
Most SSE2 intrinsics are declared in:
#include <emmintrin.h>
This header includes the SSE2 intrinsic definitions for double-precision floating-point operations, integer vector operations, memory operations, comparisons, conversions, and related functionality.
Main SSE2 data types
SSE2 code usually works with three 128-bit vector types.
| Type | Meaning | Typical contents |
|---|---|---|
__m128 | SSE single-precision vector | 4 floats |
__m128d | SSE2 double-precision vector | 2 doubles |
__m128i | SSE2 integer vector | integers of different lane widths |
This article focuses mostly on __m128d and __m128i.
Packed double and scalar double
SSE2 double-precision floating-point intrinsics usually come in two forms:
| Suffix | Meaning | Operation |
|---|---|---|
PD | Packed Double-precision | operates on both 64-bit double lanes |
SD | Scalar Double-precision | operates only on the low 64-bit double lane |
For example:
_mm_add_pd(a, b)
adds both double-precision lanes:
[ a0 + b0 | a1 + b1 ]
But:
_mm_add_sd(a, b)
adds only the low lane and copies the high lane from the first operand:
[ a0 + b0 | a1 ]
This behavior is one of the most important things to understand when reading or writing SSE2 code.
Naming conventions
SSE2 intrinsic names are easier to understand once the suffixes are familiar.
| Name fragment | Meaning |
|---|---|
_mm | SIMD intrinsic prefix |
add, sub, mul, div | arithmetic operation |
pd | packed double-precision floating-point |
sd | scalar double-precision floating-point |
epi8 | packed 8-bit integers |
epi16 | packed 16-bit integers |
epi32 | packed 32-bit integers |
epi64 | packed 64-bit integers |
si128 | 128-bit integer vector |
loadu | unaligned load |
storeu | unaligned store |
For example:
_mm_add_pd
means “add packed doubles.”
_mm_add_epi16
means “add packed 16-bit integers.”
_mm_storeu_si128
means “store an unaligned 128-bit integer vector.”
Floating-point arithmetic intrinsics
The following table summarizes the most common SSE2 double-precision arithmetic intrinsics.
In the examples below:
a = [ a0 | a1 ]
b = [ b0 | b1 ]
| Intrinsic | Instruction | Operation | Result |
|---|---|---|---|
_mm_add_pd(a, b) | ADDPD | packed add | `[a0 + b0 |
_mm_add_sd(a, b) | ADDSD | scalar add | `[a0 + b0 |
_mm_sub_pd(a, b) | SUBPD | packed subtract | `[a0 – b0 |
_mm_sub_sd(a, b) | SUBSD | scalar subtract | `[a0 – b0 |
_mm_mul_pd(a, b) | MULPD | packed multiply | `[a0 * b0 |
_mm_mul_sd(a, b) | MULSD | scalar multiply | `[a0 * b0 |
_mm_div_pd(a, b) | DIVPD | packed divide | `[a0 / b0 |
_mm_div_sd(a, b) | DIVSD | scalar divide | `[a0 / b0 |
_mm_sqrt_pd(a) | SQRTPD | packed square root | `[sqrt(a0) |
_mm_sqrt_sd(a, b) | SQRTSD | scalar square root | `[sqrt(b0) |
_mm_min_pd(a, b) | MINPD | packed minimum | `[min(a0,b0) |
_mm_min_sd(a, b) | MINSD | scalar minimum | `[min(a0,b0) |
_mm_max_pd(a, b) | MAXPD | packed maximum | `[max(a0,b0) |
_mm_max_sd(a, b) | MAXSD | scalar maximum | `[max(a0,b0) |
Notice the special case for _mm_sqrt_sd(a, b). Unlike most scalar arithmetic operations, the value being square-rooted comes from the low lane of the second operand, while the high lane is copied from the first operand.
Example: adding two doubles
This is the simplest packed double-precision SSE2 example. The function adds two pairs of doubles using one vector operation.
#include <emmintrin.h>
void add2_doubles(const double* a, const double* b, double* out)
{
__m128d va = _mm_loadu_pd(a);
__m128d vb = _mm_loadu_pd(b);
__m128d result = _mm_add_pd(va, vb);
_mm_storeu_pd(out, result);
}
If the input arrays contain:
a = [1.0, 2.0]
b = [10.0, 20.0]
then the output is:
out = [11.0, 22.0]
Example: packed vs scalar double arithmetic
Packed double instructions operate on both lanes. Scalar double instructions operate only on the low lane and copy the high lane from the first operand.
#include <emmintrin.h>
void packed_vs_scalar(double* packedOut, double* scalarOut)
{
__m128d a = _mm_setr_pd(1.0, 2.0);
__m128d b = _mm_setr_pd(10.0, 20.0);
__m128d packed = _mm_add_pd(a, b);
__m128d scalar = _mm_add_sd(a, b);
_mm_storeu_pd(packedOut, packed);
_mm_storeu_pd(scalarOut, scalar);
}
The packed result is:
packedOut = [11.0, 22.0]
The scalar result is:
scalarOut = [11.0, 2.0]
Only the first lane was added. The second lane was copied from a.
Example: processing an array of doubles
Most real SSE2 code processes arrays in chunks of two doubles.
#include <emmintrin.h>
void add_double_arrays(const double* a,
const double* b,
double* out,
int count)
{
int i = 0;
for (; i + 1 < count; i += 2)
{
__m128d va = _mm_loadu_pd(&a[i]);
__m128d vb = _mm_loadu_pd(&b[i]);
__m128d result = _mm_add_pd(va, vb);
_mm_storeu_pd(&out[i], result);
}
// Handle the remaining element if count is odd.
for (; i < count; ++i)
{
out[i] = a[i] + b[i];
}
}
The vector loop handles two doubles per iteration. The scalar cleanup loop handles the final element when the array length is odd.
Example: scale and offset an array of doubles
This example computes:
out[i] = input[i] * scale + offset
for every element in the array.
#include <emmintrin.h>
void scale_and_offset_doubles(const double* input,
double* output,
int count,
double scale,
double offset)
{
__m128d vscale = _mm_set1_pd(scale);
__m128d voffset = _mm_set1_pd(offset);
int i = 0;
for (; i + 1 < count; i += 2)
{
__m128d x = _mm_loadu_pd(&input[i]);
__m128d y = _mm_mul_pd(x, vscale);
y = _mm_add_pd(y, voffset);
_mm_storeu_pd(&output[i], y);
}
for (; i < count; ++i)
{
output[i] = input[i] * scale + offset;
}
}
_mm_set1_pd broadcasts one double value to both lanes:
_mm_set1_pd(2.0) -> [2.0 | 2.0]
This is useful when the same constant must be applied to multiple values.
Example: clamping doubles with MINPD and MAXPD
The MINPD and MAXPD instructions can be used to clamp values to a range.
The following function clamps every value to the interval:
[minValue, maxValue]
#include <emmintrin.h>
void clamp_doubles(const double* input,
double* output,
int count,
double minValue,
double maxValue)
{
__m128d vmin = _mm_set1_pd(minValue);
__m128d vmax = _mm_set1_pd(maxValue);
int i = 0;
for (; i + 1 < count; i += 2)
{
__m128d x = _mm_loadu_pd(&input[i]);
x = _mm_max_pd(x, vmin);
x = _mm_min_pd(x, vmax);
_mm_storeu_pd(&output[i], x);
}
for (; i < count; ++i)
{
double x = input[i];
if (x < minValue)
x = minValue;
if (x > maxValue)
x = maxValue;
output[i] = x;
}
}
This pattern is common in numerical code, image processing, signal processing, and physics simulations.
Integer SIMD with SSE2
SSE2 also introduced many integer SIMD operations using the __m128i type.
A __m128i register is just 128 bits. The same bits can be interpreted as different lane widths depending on the intrinsic:
16 x 8-bit integers
8 x 16-bit integers
4 x 32-bit integers
2 x 64-bit integers
For example:
| Intrinsic | Operation |
|---|---|
_mm_add_epi8(a, b) | add sixteen 8-bit integers |
_mm_add_epi16(a, b) | add eight 16-bit integers |
_mm_add_epi32(a, b) | add four 32-bit integers |
_mm_add_epi64(a, b) | add two 64-bit integers |
_mm_sub_epi8(a, b) | subtract sixteen 8-bit integers |
_mm_sub_epi16(a, b) | subtract eight 16-bit integers |
_mm_sub_epi32(a, b) | subtract four 32-bit integers |
_mm_sub_epi64(a, b) | subtract two 64-bit integers |
_mm_mullo_epi16(a, b) | multiply 16-bit integers and keep the low 16 bits |
Example: adding 32-bit integers
This function adds four 32-bit integers at a time.
#include <emmintrin.h>
void add_int32_arrays(const int* a,
const int* b,
int* out,
int count)
{
int i = 0;
for (; i + 3 < count; i += 4)
{
__m128i va = _mm_loadu_si128((const __m128i*)&a[i]);
__m128i vb = _mm_loadu_si128((const __m128i*)&b[i]);
__m128i result = _mm_add_epi32(va, vb);
_mm_storeu_si128((__m128i*)&out[i], result);
}
for (; i < count; ++i)
{
out[i] = a[i] + b[i];
}
}
The vector loop processes four integers per iteration.
Saturating arithmetic
Some SSE2 integer operations support saturation.
Normal integer addition wraps on overflow. Saturating addition clamps the result to the minimum or maximum value representable by the lane type.
For unsigned 8-bit integers:
250 + 20 = 255 // saturating
250 + 20 = 14 // wrapping modulo 256
SSE2 provides both signed and unsigned saturating operations for 8-bit and 16-bit lanes.
| Intrinsic | Meaning |
|---|---|
_mm_adds_epi8(a, b) | signed saturating add, 8-bit lanes |
_mm_adds_epi16(a, b) | signed saturating add, 16-bit lanes |
_mm_adds_epu8(a, b) | unsigned saturating add, 8-bit lanes |
_mm_adds_epu16(a, b) | unsigned saturating add, 16-bit lanes |
_mm_subs_epi8(a, b) | signed saturating subtract, 8-bit lanes |
_mm_subs_epi16(a, b) | signed saturating subtract, 16-bit lanes |
_mm_subs_epu8(a, b) | unsigned saturating subtract, 8-bit lanes |
_mm_subs_epu16(a, b) | unsigned saturating subtract, 16-bit lanes |
Saturating arithmetic is especially useful in image and audio processing, where values often need to stay within a fixed range.
Example: brighten 8-bit pixels with saturation
The following example adds a brightness value to unsigned 8-bit pixels and clamps the result to 255.
#include <emmintrin.h>
void brighten_u8(const unsigned char* input,
unsigned char* output,
int count,
unsigned char amount)
{
__m128i vamount = _mm_set1_epi8((char)amount);
int i = 0;
for (; i + 15 < count; i += 16)
{
__m128i pixels = _mm_loadu_si128((const __m128i*)&input[i]);
__m128i result = _mm_adds_epu8(pixels, vamount);
_mm_storeu_si128((__m128i*)&output[i], result);
}
for (; i < count; ++i)
{
int value = input[i] + amount;
if (value > 255)
value = 255;
output[i] = (unsigned char)value;
}
}
The SSE2 loop processes sixteen pixels per iteration.
Memory operations
SSE2 includes aligned and unaligned load/store intrinsics.
For double-precision floating-point values:
| Intrinsic | Meaning |
|---|---|
_mm_load_pd(ptr) | load two aligned doubles |
_mm_loadu_pd(ptr) | load two unaligned doubles |
_mm_store_pd(ptr, v) | store two aligned doubles |
_mm_storeu_pd(ptr, v) | store two unaligned doubles |
For integer vectors:
| Intrinsic | Meaning |
|---|---|
_mm_load_si128(ptr) | load aligned 128-bit integer vector |
_mm_loadu_si128(ptr) | load unaligned 128-bit integer vector |
_mm_store_si128(ptr, v) | store aligned 128-bit integer vector |
_mm_storeu_si128(ptr, v) | store unaligned 128-bit integer vector |
Aligned loads and stores require the memory address to be 16-byte aligned. Unaligned loads and stores work with arbitrary addresses.
For simple and safe code, use the unaligned versions unless you know that the memory is correctly aligned.
__m128d a = _mm_loadu_pd(ptr);
_mm_storeu_pd(out, a);
Modern processors handle unaligned memory accesses much better than early SSE2-era processors, but alignment can still matter in performance-critical loops.
Comparisons
SSE2 provides comparison intrinsics for packed and scalar doubles.
Examples:
| Intrinsic | Meaning |
|---|---|
_mm_cmpeq_pd(a, b) | compare packed doubles for equality |
_mm_cmplt_pd(a, b) | compare packed doubles for less-than |
_mm_cmple_pd(a, b) | compare packed doubles for less-than-or-equal |
_mm_cmpgt_pd(a, b) | compare packed doubles for greater-than |
_mm_cmpge_pd(a, b) | compare packed doubles for greater-than-or-equal |
_mm_cmpneq_pd(a, b) | compare packed doubles for not-equal |
The result of a comparison is a mask. Each lane is either all bits set or all bits clear.
That mask can then be used with logical operations to select or combine values.
Logical operations
SSE2 includes bitwise logical operations for floating-point and integer vectors.
For double-precision vectors:
| Intrinsic | Meaning |
|---|---|
_mm_and_pd(a, b) | bitwise AND |
_mm_or_pd(a, b) | bitwise OR |
_mm_xor_pd(a, b) | bitwise XOR |
_mm_andnot_pd(a, b) | bitwise AND NOT |
For integer vectors:
| Intrinsic | Meaning |
|---|---|
_mm_and_si128(a, b) | bitwise AND |
_mm_or_si128(a, b) | bitwise OR |
_mm_xor_si128(a, b) | bitwise XOR |
_mm_andnot_si128(a, b) | bitwise AND NOT |
These operations are often used with comparison masks.
Conversions
SSE2 includes conversion intrinsics between double-precision floating-point values and integers.
Some commonly used conversions are:
| Intrinsic | Meaning |
|---|---|
_mm_cvtepi32_pd(a) | convert two 32-bit integers to two doubles |
_mm_cvtpd_epi32(a) | convert two doubles to 32-bit integers using current rounding mode |
_mm_cvttpd_epi32(a) | convert two doubles to 32-bit integers using truncation |
_mm_cvtpd_ps(a) | convert two doubles to two floats |
_mm_cvtps_pd(a) | convert two floats to two doubles |
The difference between rounding and truncating conversions matters.
For example:
3.9 converted with rounding may become 4
3.9 converted with truncation becomes 3
Use the intrinsic that matches the numerical behavior you need.
Common pitfalls
SSE2 intrinsics are powerful, but there are several details that can cause mistakes.
Confusing packed and scalar operations
PD operations work on both double lanes.
SD operations work only on the low double lane and copy the high lane from the first operand.
__m128d a = _mm_setr_pd(1.0, 2.0);
__m128d b = _mm_setr_pd(10.0, 20.0);
__m128d r = _mm_add_sd(a, b);
The result is:
[11.0 | 2.0]
not:
[11.0 | 22.0]
Forgetting that _mm_sqrt_sd(a, b) uses b
Most scalar arithmetic operations look like:
low result = a0 op b0
high result = a1
But _mm_sqrt_sd(a, b) computes:
low result = sqrt(b0)
high result = a1
That makes it slightly different from the other scalar double operations.
Assuming MIN and MAX are always simple mathematical min/max
MINPD, MINSD, MAXPD, and MAXSD have specific floating-point behavior, especially for NaN values and signed zero.
If your data may contain NaNs, invalid values, or results from division by zero, do not assume that these instructions behave exactly like a high-level mathematical minimum or maximum. Check the processor documentation for the exact behavior.
Ignoring alignment
Aligned load/store intrinsics require 16-byte alignment.
_mm_load_pd(ptr); // ptr must be aligned
_mm_loadu_pd(ptr); // ptr may be unaligned
Using an aligned load on an unaligned address can crash or produce a fault on older or stricter systems. Use unaligned loads unless alignment is guaranteed.
Processing only vector-sized chunks
Packed double SSE2 code processes two doubles per iteration. Integer code may process 16, 8, 4, or 2 elements per iteration depending on lane width.
If the array length is not a multiple of the vector width, handle the remaining elements with a scalar cleanup loop.
Assuming hand-written intrinsics are always faster
Modern compilers can auto-vectorize many simple loops. Intrinsics are useful when you need explicit control, but they also make code harder to read and maintain.
Before rewriting scalar code with intrinsics:
- Write clear scalar code.
- Compile with optimization enabled.
- Measure performance.
- Inspect the generated assembly.
- Use intrinsics only where they improve the measured hot path.
Mixing SSE2 and older x87 floating-point behavior
On modern x86-64 systems, floating-point code usually uses SSE/SSE2 instructions. Older 32-bit x86 code may use the x87 floating-point unit.
x87 uses an extended-precision internal format, while SSE2 double operations use 64-bit double-precision lanes. This can produce small numerical differences.
For numerical tests, compare floating-point results with a tolerance rather than expecting exact bit-for-bit equality.
Build notes
On x86-64, SSE2 is generally available as a baseline instruction set. On 32-bit x86, very old processors may not support SSE2, so software targeting old 32-bit systems may need runtime CPU feature detection.
Example GCC or Clang build command:
gcc -O2 -msse2 example.c -o example
For C++:
g++ -O2 -msse2 example.cpp -o example
On MSVC, include the correct headers and build with optimization enabled. For modern x64 builds, SSE2 support is normally part of the baseline target.
Complete example program
The following program demonstrates packed and scalar double addition.
#include <stdio.h>
#include <emmintrin.h>
static void print2(const char* name, __m128d value)
{
double out[2];
_mm_storeu_pd(out, value);
printf("%s = [%f, %f]\n", name, out[0], out[1]);
}
int main()
{
__m128d a = _mm_setr_pd(1.0, 2.0);
__m128d b = _mm_setr_pd(10.0, 20.0);
__m128d packedAdd = _mm_add_pd(a, b);
__m128d scalarAdd = _mm_add_sd(a, b);
print2("a", a);
print2("b", b);
print2("_mm_add_pd(a, b)", packedAdd);
print2("_mm_add_sd(a, b)", scalarAdd);
return 0;
}
Expected output:
a = [1.000000, 2.000000]
b = [10.000000, 20.000000]
_mm_add_pd(a, b) = [11.000000, 22.000000]
_mm_add_sd(a, b) = [11.000000, 2.000000]
Summary
SSE2 extends SSE in two major ways.
First, it adds double-precision floating-point SIMD operations. With __m128d, a single XMM register can hold two 64-bit doubles, and packed operations such as _mm_add_pd, _mm_mul_pd, and _mm_div_pd operate on both values in parallel.
Second, it adds integer SIMD operations using __m128i, allowing one 128-bit register to hold sixteen 8-bit integers, eight 16-bit integers, four 32-bit integers, or two 64-bit integers.
The most important concepts to remember are:
PDmeans packed double: both double lanes are used.SDmeans scalar double: only the low double lane is used.__m128dis used for two double-precision values.__m128iis used for integer vectors.- memory alignment matters for aligned loads and stores.
- scalar cleanup is needed when array lengths are not multiples of the vector width.
- intrinsics should be used where they improve measured performance, not just because they look lower-level.
SSE2 is no longer new, but it remains important. It is a baseline SIMD instruction set on modern x86-64 systems, and understanding it provides a solid foundation for later SIMD extensions such as SSE3, SSSE3, SSE4, AVX, AVX2, and AVX-512.
References
- Intel Intrinsics Guide
https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html - Intel 64 and IA-32 Architectures Software Developer Manuals
https://www.intel.com/content/www/us/en/developer/articles/technical/intel-sdm.html - Microsoft x86/x64 intrinsics list
https://learn.microsoft.com/en-us/cpp/intrinsics/x86-intrinsics-list - Microsoft x64/AMD64 intrinsics list
https://learn.microsoft.com/en-us/cpp/intrinsics/x64-amd64-intrinsics-list




