
Scraping content from websites can be a useful tool for gathering information or automating certain tasks. In C#, there are several libraries available that can help make this process easier. In this blog post, we will cover how to use the HtmlAgilityPack library to scrape content from websites in C#.
The HtmlAgilityPack library is a powerful and flexible HTML parser that allows you to easily manipulate and traverse HTML documents.
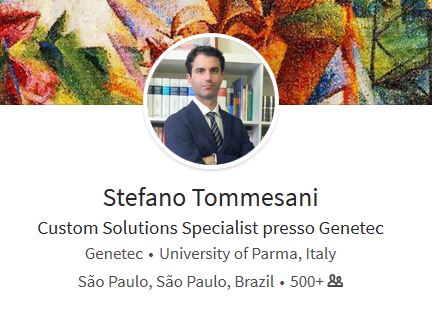
Suppose we have to extract the profile names from a well-known site:
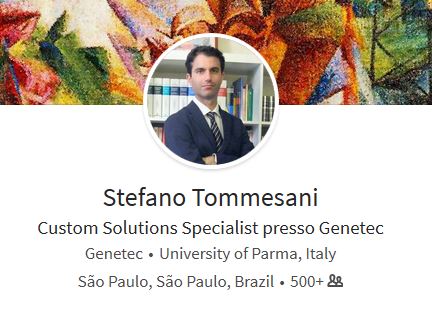
The first step is identifying the element in the HTML page containing the profile name. In Chrome, select the name of the profile, right-click on it and select Analyze element in the popup menu, and we will get here:

We have all the bits of information we need, the name of the profile is hosted in an h1 element with a class containing the pv-top-card-section__name attribute. The troubling point is that the class contains more than an attribute, and we are not interested in specifying the other ones when searching for the right element in the page. Time to write some C# code. Assuming that the HTML code of the page was already digested by the HTMLAgilityPack package, the following function will search the correct element inside the page and return the inner text data:
public string GetItemText(HtmlDocument htmlDoc, string itemType, string tag, string value) { if (htmlDoc.DocumentNode != null) { var findclasses = htmlDoc.DocumentNode .Descendants(itemType) .Where(d => d.Attributes.Contains(tag) && d.Attributes[tag].Value.Contains(value) ); var itemList = findclasses.ToList(); if (itemList.Any()) return CleanUpItem(itemList.First().InnerText); } return string.Empty; }
The function will search for a specific element type (in this case, h1) that contains the given attribute (in this case, pv-top-card-section__name), so this invoke will return the name of the profile:
parsedProfile.Name = GetItemText(htmlDoc, "h1", "pv-top-card-section__name");
What does the CleanUpItem call do, you say? Just some cleaning of the inner text of the element:
private string CleanUpItem(string item) { // decode & and other HTML encodings var decodedItem = WebUtility.HtmlDecode(item); // split lines containing new lines chars, then combine them again, skipping empty lines var lines = decodedItem.Split( new[] { "\r\n", "\r", "\n", "\\n" }, StringSplitOptions.None ); var formattedLines = lines.Where(n => !String.IsNullOrWhiteSpace(n)).Select(n => n.Trim()); if (formattedLines.Count() > 1) return String.Join(" ", formattedLines); else return formattedLines.FirstOrDefault(); }
So now, by a quick investigation with Chrome, and a C# code fragment, we can easily scrape the information from the web pages. The HtmlAgilityPack library provides a convenient and powerful way to scrape content from websites in C#. By using the HtmlDocument class, you can easily parse HTML documents, navigate the HTML tree, and extract the information you need. This can be useful for a wide range of applications, such as data mining, web scraping, or automating repetitive tasks.


