
Data referenced by a program can have temporal (data will be used again) or spatial (data will be in adjacent locations, such as the same cache line) locality, but some multimedia data types are referenced once and not reused in the immediate future (called non-temporal data). Thus, non-temporal data should not overwrite the application?s cached code and data: the cacheability control instructions enable the programmer to control caching so that non-temporal accesses will minimize cache pollution.
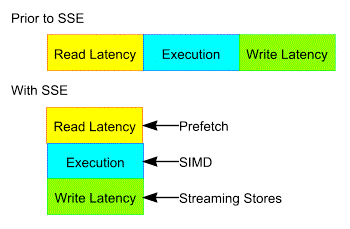
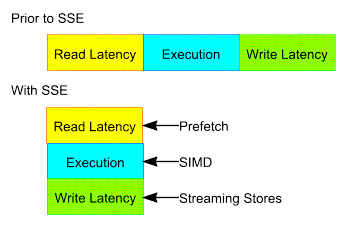
In addition, the execution engine needs to be fed such that it does not become stalled waiting for data. SSE allows the programmer to prefetch data long before its final use to minimize memory latency. Prior to SSE, read miss latency and execution and subsequent store miss latency comprised total execution in a serial fashion. SSE lets read miss latency overlap execution via the use of prefetching, and it allowes store miss latency to be reduced and overlap execution via streaming stores.
The following three instructions provide programmatic control for minimizing cache pollution when writing data to memory from either MMX or SSE registers.
MASKMOVQ stores data from an MMX register to the location specified by the EDI register. The most significant bit in each byte of the second MMX mask register is used to selectively write the data of the first register on a per-byte basis. This instruction does not write-allocate (i.e., the processor will not fetch the corresponding cache line into the cache hierarchy, prior to performing the store), and so minimizes cache pollution.
MOVNTQ stores data from an MMX register to memory; this instruction is implicitly weakly-ordered, does not write-allocate, and minimizes cache pollution.
MOVNTPS stores data from a SIMD floating-point register to memory. The memory address must be aligned to a 16-byte boundary; if it is not aligned, a general protection exception will occur. The instruction is implicitly weakly ordered, does not write-allocate, and minimizes cache pollution.
PREFETCH loads either non-temporal data or temporal data in the specified cache level. As this instruction merely provides a hint to the hardware, it will not generate exceptions or faults.
SFENCE guarantees that every store instruction that precedes the store fence instruction in program order is globally visible before any store instruction that follows the fence. The SFENCE instruction provides an efficient way of ensuring ordering between routines that produce weakly-ordered results and routines that consume this data. The use of weakly-ordered memory types can be important under certain data sharing relation-ships, such as a producer-consumer relationship. The use of weakly-ordered memory can make the assembling of data more efficient, but care must be taken to ensure that the consumer obtains the data that the producer intended it to see.


