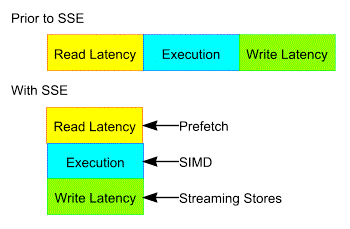
A basic building block operation in geometry involves computing divisions and square roots. For instance, transformation often involves dividing each x, y, z coordinate by the W perspective coordinate; normalization is another common geometry operation, which requires the computation of 1/square-root. In order to optimize these cases, SSE introduces two…