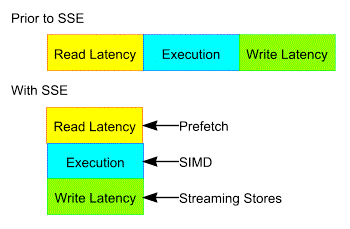
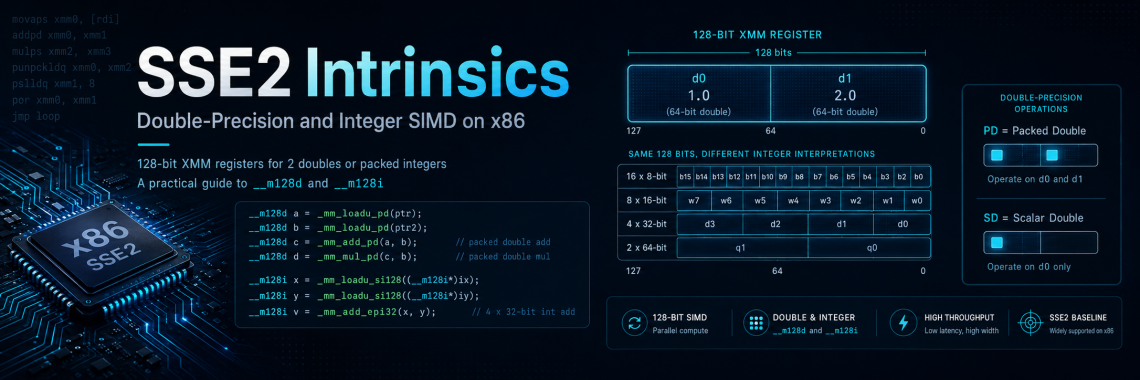
MOVAPS transfers 128 bits of packed data from memory to SIMD floating-point registers and vice versa, or between SIMD floating-point registers, while MOVUPS makes no assumption for alignment. MOVHPS transfers 64 bits of packed data from memory to the upper two fields of a SIMD floating-point register and vice versa,…